publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
- DADP: Domain Adaptive Diffusion PolicyPengcheng Wang, Qinghang Liu, Haotian Lin, Yiheng Li, Guojian Zhan, Masayoshi Tomizuka, and 1 more author2026In Submission
Learning domain-adaptive policies that can generalize to unseen transition dynamics remains a fundamental challenge in learning-based control. Substantial progress has been made through domain representation learning to capture domain-specific information, thus enabling domain-aware decision making. We analyze the process of learning domain representations through dynamical prediction and find that selecting contexts adjacent to the current step causes the learned representations to entangle static domain information with varying dynamical properties. Such mixture can confuse the conditioned policy, thereby constraining zero-shot adaptation. To tackle the challenge, we propose DADP (Domain-Adaptive Diffusion Policy), which achieves robust adaptation through unsupervised disentanglement and domain-aware diffusion injection. First, we introduce Lagged Context Dynamical Prediction, a strategy that conditions future state estimation on a historical offset context; by increasing this temporal gap, we unsupervisedly disentangle static domain representations by filtering out transient properties. Second, we integrate the learned domain representations directly into the generative process by biasing the prior distribution and reformulating the diffusion target. Extensive experiments on challenging benchmarks across locomotion and manipulation demonstrate the superior performance and the generalizability of DADP over prior methods. More visualization results are available on the website.

2025
-
 Self-Improving Vision-Language-Action Models with Data Generation via Residual RLarXiv preprint arXiv:2511.00091, 2025ICLR2026
Self-Improving Vision-Language-Action Models with Data Generation via Residual RLarXiv preprint arXiv:2511.00091, 2025ICLR2026Supervised fine-tuning (SFT) has become the de facto post-training strategy for large vision-language-action (VLA) models, but its reliance on costly human demonstrations limits scalability and generalization. We propose Probe, Learn, Distill PLD, a plug-and-play framework that improves VLAs through residual reinforcement learning and distribution-aware data collection. In Stage 1 (specialist acquisition), we freeze the VLA backbone and train lightweight residual actors via off-policy RL. These specialists take over in states where the base policy fails, thereby probing failure regions of the generalist. In Stage 2 (data collection), we employ a hybrid rollout scheme that biases residual interventions toward states frequently visited by the base policy, aligning collected trajectories with the generalist’s deployment distribution while capturing recovery behaviors. In Stage 3 (fine-tuning), these curated trajectories are distilled back into the generalist with standard SFT, applicable to both flow-matching and autoregressive heads. We evaluate PLD across diverse settings: it achieves a near-saturated 99 % task success rate on the LIBERO benchmark, delivers over 50 % performance gains in SimplerEnv, and demonstrates practicality on real-world Franka arm manipulation tasks. We further provide ablations showing that residual policy probing and distribution-aware replay are key to collecting deployment-aligned data that improves VLAs’ capabilities on both seen and unseen tasks. Our results demonstrate that RL-generated, policy-aligned data can surpass teleoperation-only demonstrations, offering a scalable path toward self-improving VLA models.
@article{Xiao2025Improve, title = {Self-Improving Vision-Language-Action Models with Data Generation via Residual RL}, author = {Xiao, Wenli and Lin, Haotian and Peng, Andy and Xue, Haoru and He, Tairan and Xie, Yuqi and Hu, Fengyuan and Wu, Jimmy and Luo, Zhengyi and Fan, Linxi and Shi, Guanya and Zhu, Yuke}, journal = {arXiv preprint arXiv:2511.00091}, year = {2025}, note = {ICLR2026}, } -
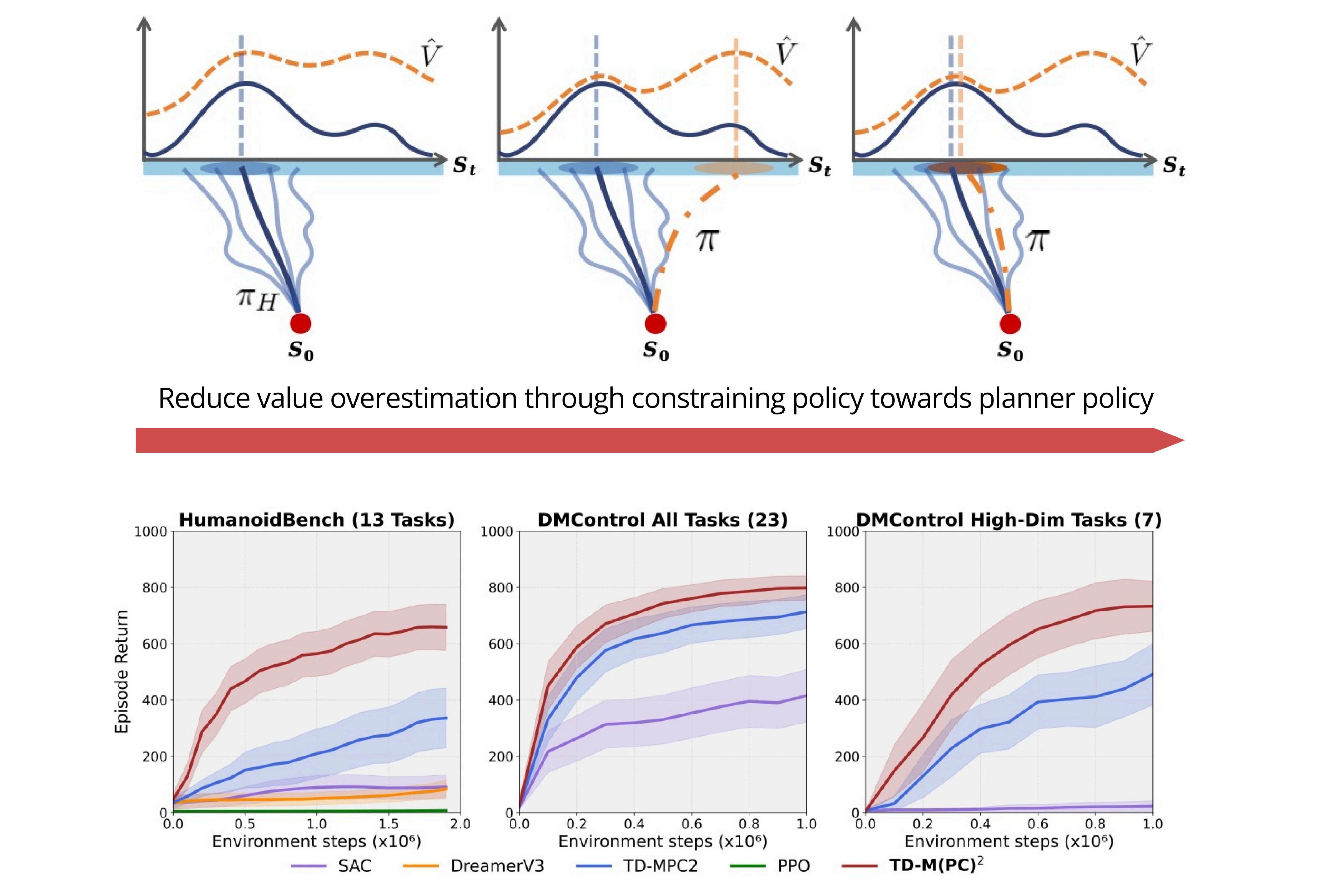 TD-M (PC) \^ 2: Improving Temporal Difference MPC Through Policy ConstraintarXiv preprint arXiv:2502.03550, 2025L4DC2026
TD-M (PC) \^ 2: Improving Temporal Difference MPC Through Policy ConstraintarXiv preprint arXiv:2502.03550, 2025L4DC2026Model-based reinforcement learning (MBRL) algorithms that integrate model predictive control with learned value or policy priors have shown great potential to solve complex continuous control problems. However, existing practice relies on online planning to collect high-quality data, resulting in value learning that is entirely dependent on off-policy experiences. Contrary to the belief that value learned from model-free policy iteration within this framework is sufficiently accurate and expressive, we found that severe value overestimation bias occurs, especially in high-dimensional tasks. Through both theoretical analysis and empirical evaluations, we identify that this overestimation stems from a structural policy mismatch: the divergence between the exploration policy induced by the model-based planner and the exploitation policy evaluated by the value prior. To improve value learning, we emphasize conservatism that mitigates out-of-distribution queries. The proposed method, TD-M(PC)\(^2\), addresses this by applying a soft-constrained policy update—a minimalist yet effective solution that can be seamlessly integrated into the existing plan-based MBRL pipeline without incurring additional computational overhead. Extensive experiments demonstrate that the proposed approach improves performance over baselines by large margins, particularly in 61-DoF humanoid control tasks.
@article{lin2025td, title = {TD-M (PC) $\^{} 2$: Improving Temporal Difference MPC Through Policy Constraint}, author = {Lin, Haotian and Wang, Pengcheng and Schneider, Jeff and Shi, Guanya}, journal = {arXiv preprint arXiv:2502.03550}, year = {2025}, note = {L4DC2026} } -
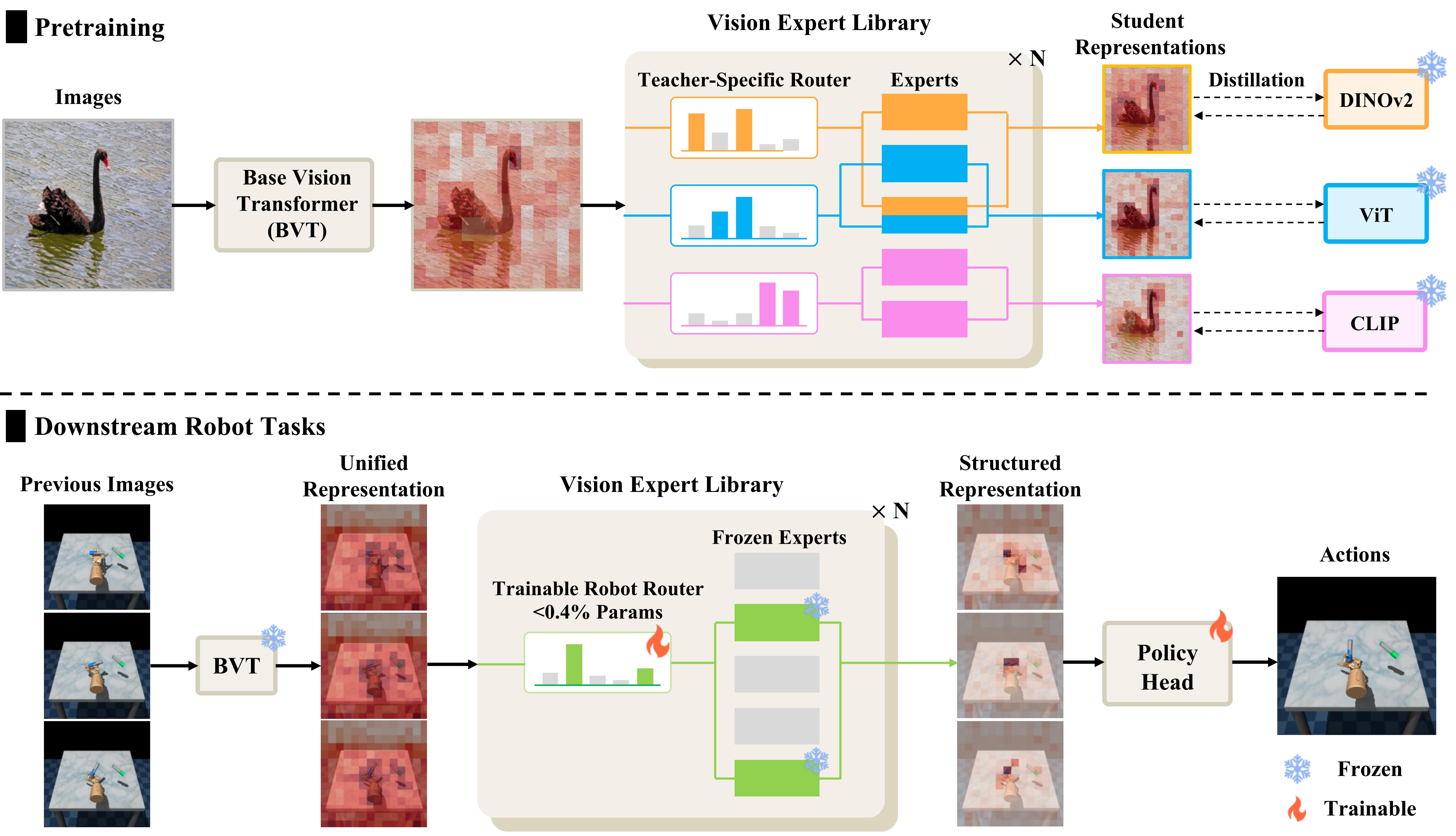 VER: Vision Expert Transformer for Robot Learning via Foundation Distillation and Dynamic RoutingarXiv preprint arXiv:2510.05213, 2025ICLR2026
VER: Vision Expert Transformer for Robot Learning via Foundation Distillation and Dynamic RoutingarXiv preprint arXiv:2510.05213, 2025ICLR2026Pretrained vision foundation models (VFMs) advance robotic learning via rich visual representations, yet individual VFMs typically excel only in specific domains, limiting generality across tasks. Distilling multiple VFMs into a unified representation for policy can mitigate this limitation but often yields inflexible task-specific feature selection and requires costly full re-training to incorporate robot-domain knowledge. We propose VER, a Vision Expert transformer for Robot learning. During pretraining, VER distills multiple VFMs into a vision expert library. It then fine-tunes only a lightweight routing network (fewer than 0.4% of parameters) to dynamically select task-relevant experts from the pretrained library for downstream robot tasks. We further introduce Patchwise Expert Routing with Curriculum Top-K Annealing to improve both flexibility and precision of dynamic expert selection. Moreover, VER supports parameter-efficient finetuning for scalable expert utilization and adaptive robot-domain knowledge integration. Across 17 diverse robotic tasks and multiple policy heads, VER achieves state-of-the-art performance. We find that VER reduces large-norm outliers in task-irrelevant regions (e.g., background) and concentrates on task-critical regions.
@article{wang2025ver, title = {VER: Vision Expert Transformer for Robot Learning via Foundation Distillation and Dynamic Routing}, author = {Wang, Yixiao and Huo, Mingxiao and Liang, Zhixuan and Du, Yushi and Sun, Lingfeng and Lin, Haotian and Shang, Jinghuan and Peng, Chensheng and Bansal, Mohit and Ding, Mingyu and others}, journal = {arXiv preprint arXiv:2510.05213}, year = {2025}, note = {ICLR2026} }



2024
-
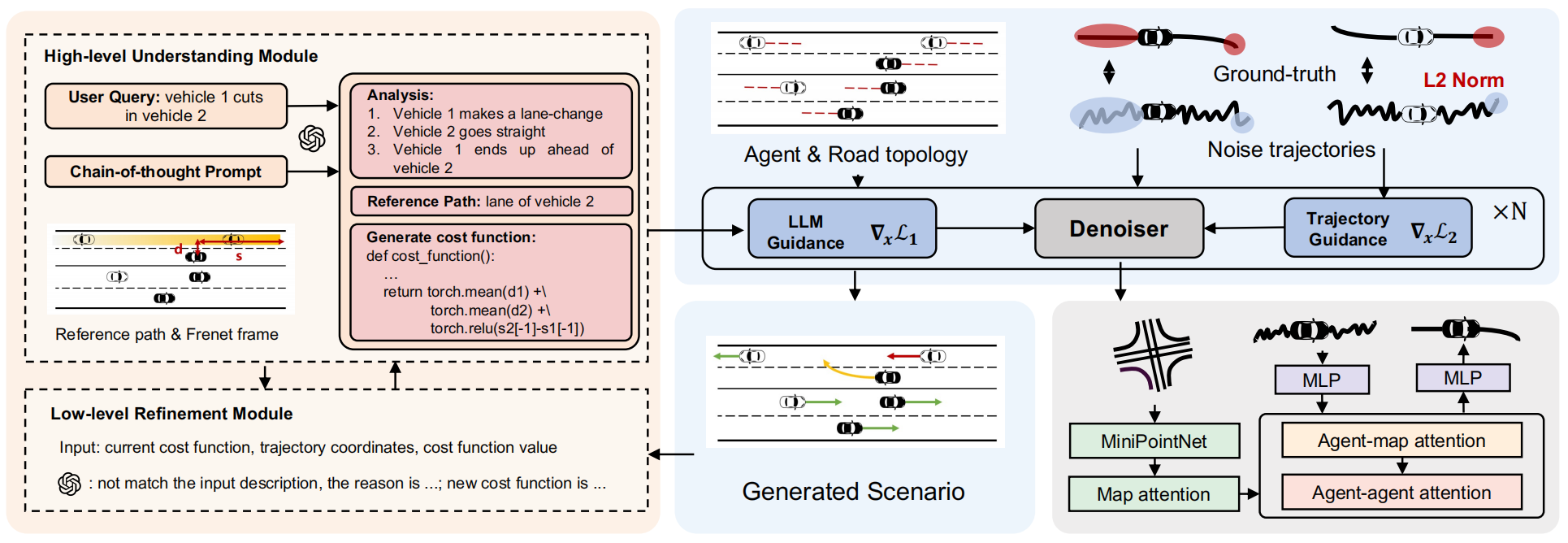 Controllable traffic simulation through llm-guided hierarchical chain-of-thought reasoningZhiyuan Liu, Leheng Li, Yuning Wang, Haotian Lin, Zhizhe Liu, Lei He, and 1 more authorarXiv preprint arXiv:2409.15135, 2024IROS2025
Controllable traffic simulation through llm-guided hierarchical chain-of-thought reasoningZhiyuan Liu, Leheng Li, Yuning Wang, Haotian Lin, Zhizhe Liu, Lei He, and 1 more authorarXiv preprint arXiv:2409.15135, 2024IROS2025@article{liu2024controllable, title = {Controllable traffic simulation through llm-guided hierarchical chain-of-thought reasoning}, author = {Liu, Zhiyuan and Li, Leheng and Wang, Yuning and Lin, Haotian and Liu, Zhizhe and He, Lei and Wang, Jianqiang}, journal = {arXiv preprint arXiv:2409.15135}, year = {2024}, note = {IROS2025}, } -
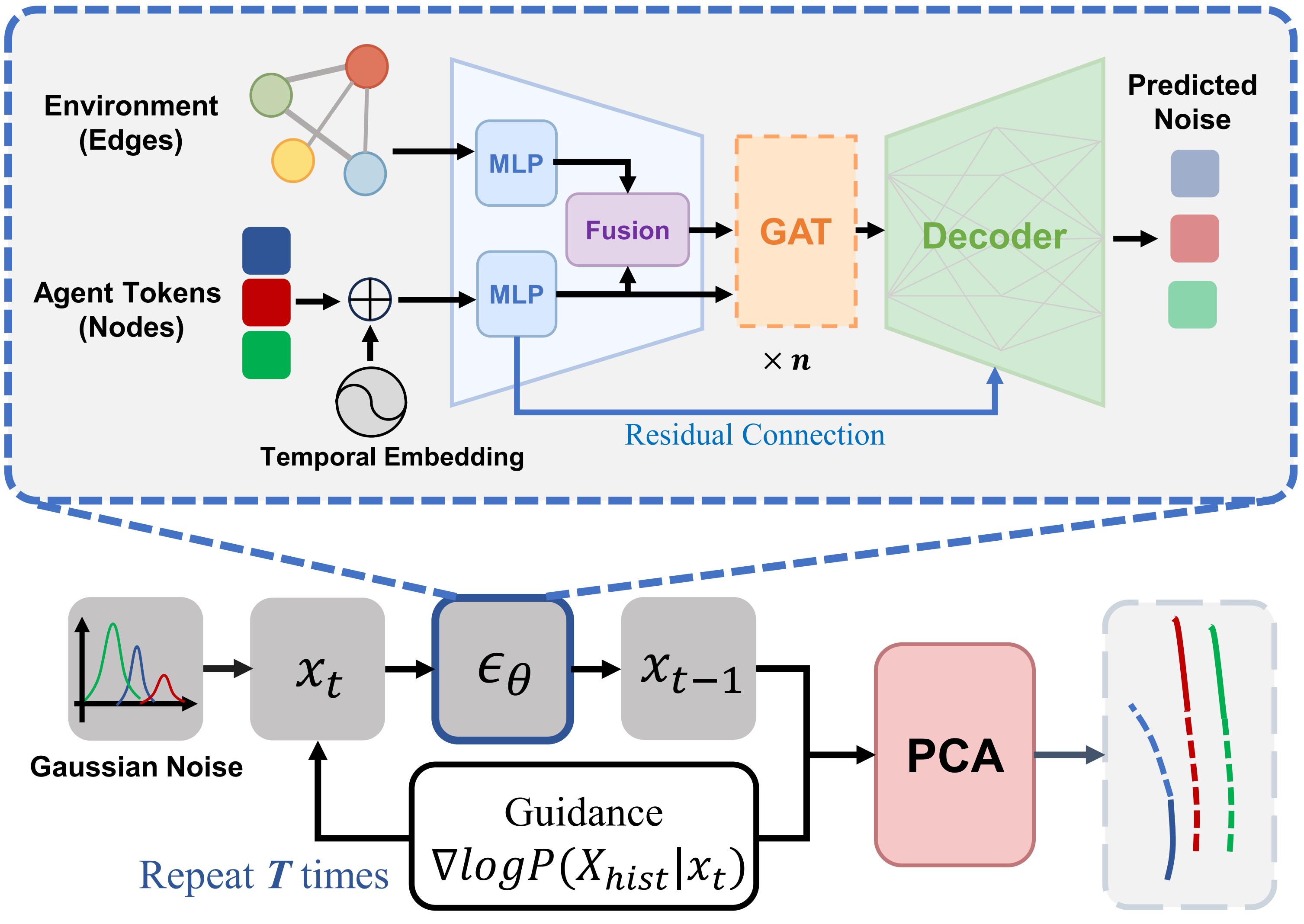 Joint pedestrian trajectory prediction through posterior samplingIn 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024IROS2024
Joint pedestrian trajectory prediction through posterior samplingIn 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024IROS2024Joint pedestrian trajectory prediction has long grappled with the inherent unpredictability of human behaviors. Recent works employing conditional diffusion models in trajectory prediction have exhibited notable success. Nevertheless, the heavy dependence on accurate historical data results in their vulnerability to noise disturbances and data incompleteness. To improve the robustness and reliability, we introduce the Guided Full Trajectory Diffuser (GFTD), a novel diffusion-based framework that translates prediction as the inverse problem of spatial-temporal inpainting and models the full joint trajectory distribution which includes both history and the future. By learning from the full trajectory and leveraging flexible posterior sampling methods, GFTD can produce accurate predictions while improving the robustness that can generalize to scenarios with noise perturbation or incomplete historical data. Moreover, the pre-trained model enables controllable generation without an additional training budget. Through rigorous experimental evaluation, GFTD exhibits superior performance in joint trajectory prediction with different data quality and in controllable generation tasks
@inproceedings{lin2024joint, title = {Joint pedestrian trajectory prediction through posterior sampling}, author = {Lin, Haotian and Wang, Yixiao and Huo, Mingxiao and Peng, Chensheng and Liu, Zhiyuan and Tomizuka, Masayoshi}, booktitle = {2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, pages = {5672--5679}, year = {2024}, organization = {IEEE}, note = {IROS2024} }


2023
-
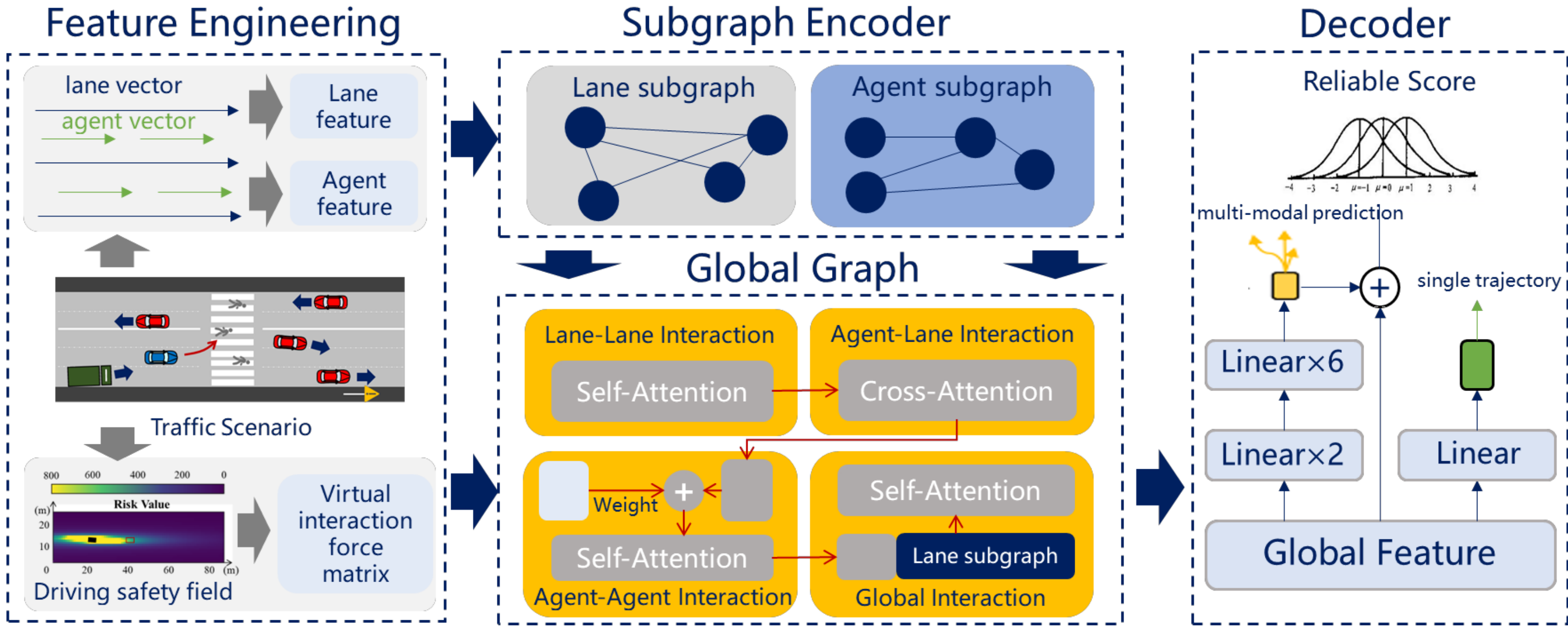 Vif-gnn: A novel agent trajectory prediction model based on virtual interaction force and gnnYuning Wang, Zhiyuan Liu, Haotian Lin, Jinhao Li, Ruochen Li, and Jianqiang WangIn 2023 IEEE Intelligent Vehicles Symposium (IV), 2023IV2023
Vif-gnn: A novel agent trajectory prediction model based on virtual interaction force and gnnYuning Wang, Zhiyuan Liu, Haotian Lin, Jinhao Li, Ruochen Li, and Jianqiang WangIn 2023 IEEE Intelligent Vehicles Symposium (IV), 2023IV2023@inproceedings{wang2023vif, title = {Vif-gnn: A novel agent trajectory prediction model based on virtual interaction force and gnn}, author = {Wang, Yuning and Liu, Zhiyuan and Lin, Haotian and Li, Jinhao and Li, Ruochen and Wang, Jianqiang}, booktitle = {2023 IEEE Intelligent Vehicles Symposium (IV)}, pages = {1--7}, year = {2023}, organization = {IEEE}, note = {IV2023} }
